2017年我最重要的目标之一就是坚持写博客。
本文技术栈:Jekyll, liquid, Azure Search, Node.js, html, javascript, xml。
坚持阅读本文默认为已经具备以上技术栈,否则后果不负。
作为一个(自诩😝)全栈攻城狮,写博客这么一件稀松平常的事情,也不能写得太平常了。
首先,要构建一个适合Geeker的高逼格的个人博客,一定不是博客园、CSDN,也不是现在比较流行的简书。所以,在死了很多脑细胞之后,最终选定了Github+Jekyll,来构建高效、静态的独立个人站点,并且用最适合码字的Markdown书写。
当然,因为这是一个静态博客的平台,为了让它能有各种动态酷炫的效果,我也是操碎心了,虽然借用了别人的模板,但也是爬了各种坑,到最后,还添加了我需要的分类、搜索、草稿文章标识等功能。
然而,程序猿总是有点洁癖和强迫症的,lunr.js的搜索对中文的支持实在是不堪,在没有服务器端的支持下,只能对中文进行简单搜索,还是无法支持中文分词。转念一想,我软有一个这么强大的搜索服务,为什么不能做一个整合呢。再一研究,居然免费版也足够我使用,心动不如行动,于是乎,就有了我这第一篇博客。
Azure背景简述
什么叫撸羊毛?就是占便宜嘛,今天我们用Azure这样一个商业云服务,免费为我们提供全文搜索服务。 Azure分为全球版和中国版,都有很多免费使用的方式,足够大家针对开发、测试和小型应用场景。以下渠道可以试用Azure:
- 全球版,免费注册,送200美金额度;中国版,一元注册试用账号,1500元人民币额度。
- MSDN订阅可以免费获取全球版25美金/月的额度。
- 微软员工可以免费获取全球版150美金/月的额度。
目前Azure Search只在全球版Azure提供,将来也会进入中国。
准备要搜索的数据
为了让Azure Search能搜索全站的文章,我们必须把所有文章的数据集合到一个文件中。Jekyll有一个官方插件jekyll-feed,可以把所有文章用一个RSS形式整理起来,作为一个RSS订阅给用户使用。但是,这里面生成的RSS文件,对于文章正文内容只有摘要,没有全部内容,所以我们需要略微改写。参考了all.xml,再根据我的博客配置情况作了修改:
- 禁止了继承config.xml的全局设置
- 修正了几个bug,并调整了一些格式
---
layout: null #禁用掉全局模板页的设置, added by Hollis Yao
---
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom" xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel>
<title>{{ site.title | xml_escape }}</title>
<description>{{ site.description | xml_escape }}</description>
<link>{{ site.url }}{{ site.baseurl }}/</link>
<atom:link href="{{ "/allfeed.xml" | prepend: site.baseurl | prepend: site.url }}" rel="self" type="application/rss+xml" />
<pubDate>{{ site.time | date_to_rfc822 }}</pubDate>
<lastBuildDate>{{ site.time | date_to_rfc822 }}</lastBuildDate>
<generator>Jekyll v{{ jekyll.version }}</generator>
{% for post in site.posts %}
<item>
<title>{{ post.title | xml_escape }}</title>
{% if post.author %}
<dc:creator>{{ post.author | xml_escape }}</dc:creator>
{% endif %}
<description>{{ post.content | xml_escape }}</description>
<pubDate>{{ post.date | date: "%a, %d %b %Y %H:%M:%S %z" }}</pubDate>
<link>{{ post.url | prepend: site.baseurl | prepend: site.url }}</link>
<guid isPermaLink="true">{{ post.url | prepend: site.baseurl | prepend: site.url }}</guid>
{% for category in post.categories %}
<category>{{ category }}</category>
{% endfor %}
{% for tag in post.tags %}
<category>{{ tag | xml_escape }}</category>
{% endfor %}
</item>
{% endfor %}
</channel>
</rss>
完整文件在这里allfeed.xml
配置Azure Search
在这个章节里面,我们会创建Azure Search服务,并进行相关配置,以便搜索服务能够正常运行在博客网站。 接下来的配置会基于Node.js的环境来运行,所以必须先在本地安装Node.js环境。
在Windows 10安装配置Node.js
进入官网https://nodejs.org/en/,找到LTS版本,点击下载,得到安装文件之后,一路Next,安装完毕。
进入cmd,执行一些测试验证node.js安装成功。
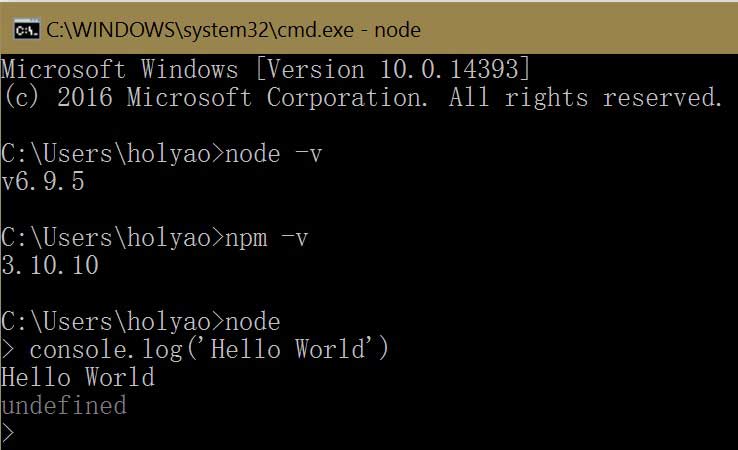
配置Node.js
npm是node.js模块管理插件,也是node如此大红大紫最重要的工具,所以我们必须系统的配置好npm,让它更好的发挥作用。
- 配置npm的全局模块和cache路径,在在nodejs的安装目录中新建文件夹:node_global和node_cache。
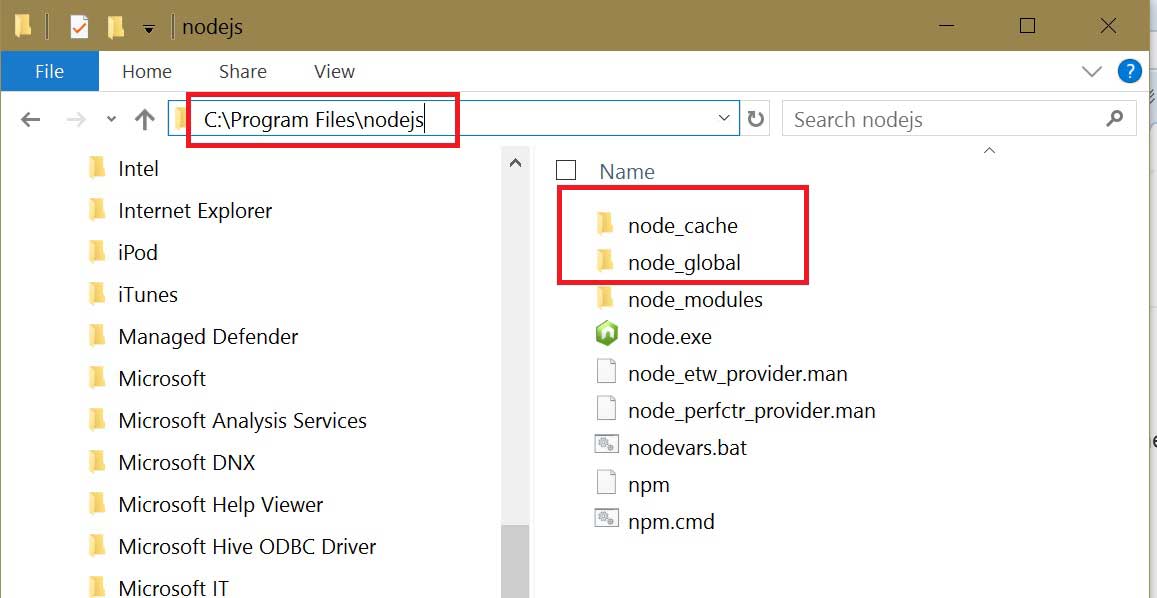
- 在cmd中输入以下命令:设置对应的路径映射。
npm config set prefix "C:\Program Files\nodejs\node_global" npm config set cache "C:\Program Files\nodejs\node_cache" - 尝试安装express模块,在命令行中输入:npm install express -g (-g表示全局安装即安装到node_global目录下)。
- 查看系统环境变量:鼠标右键单击我的电脑→属性→高级系统设置→环境变量→在系统变量下新建NODE_PATH并输入”C:\Program Files\nodejs\node_global\node_modules”。
- 重新打开cmd,让刚才设置的系统变量生效,输入node,然后再输入”require(‘express’)”测试node模块的全局路径是否配置正确。 至此,npm的配置即完成了。
创建Azure Search服务
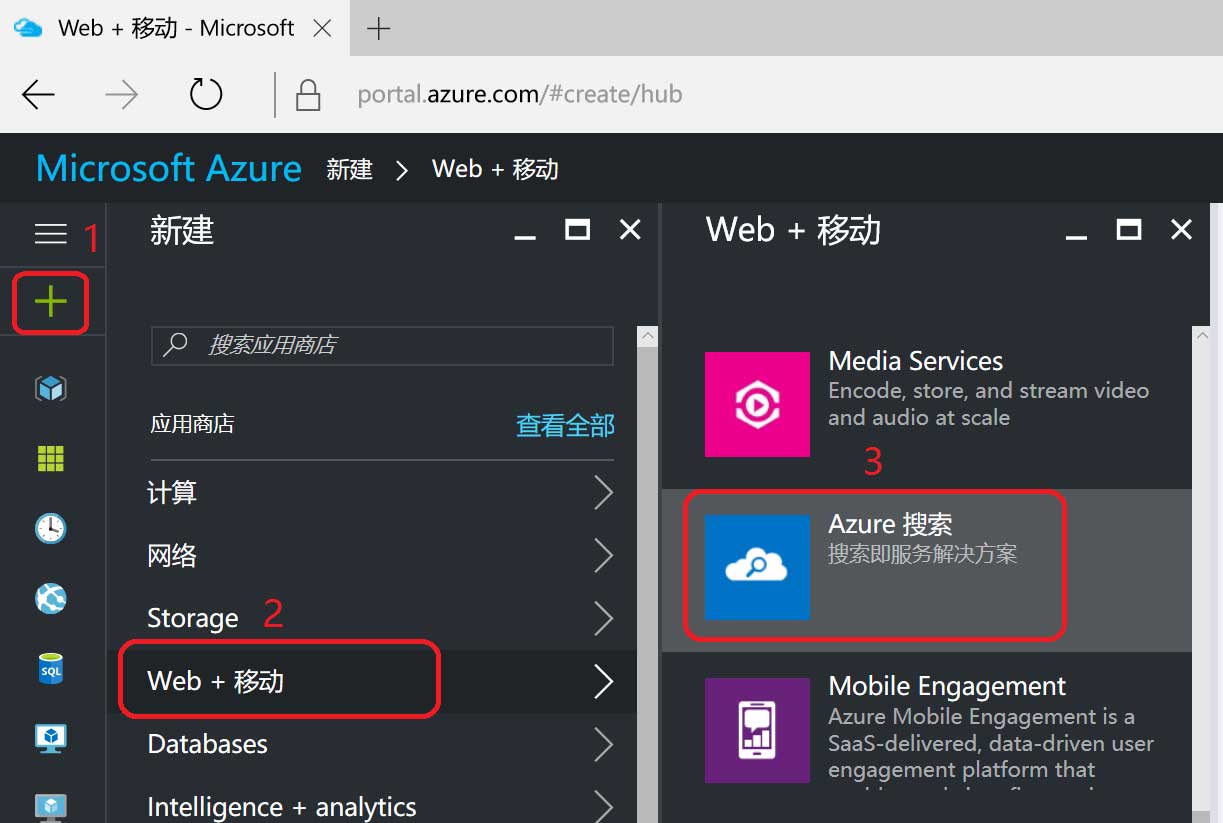
打开浏览器,输入portal.azure.com,进入Azure全球版管理门户,登陆之后,进入主界面,依次按照下图所示点击
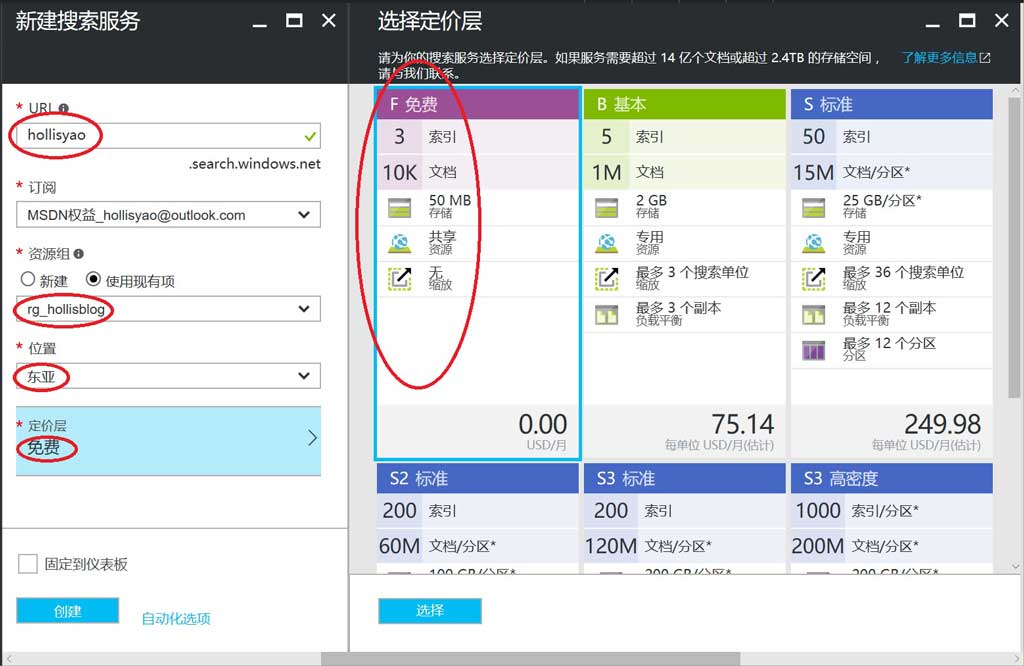
 在新建搜索服务输入相关信息,确保选中免费定价级别的服务即可,检查输入信息完毕之后,点击创建,稍等片刻,搜索服务即创建完成。
在新建搜索服务输入相关信息,确保选中免费定价级别的服务即可,检查输入信息完毕之后,点击创建,稍等片刻,搜索服务即创建完成。
创建索引和添加数据
要使用Azure Search,就必须先为它建立索引结构。 让我们先了解一下Azure Search,可通过两种方法在数据中填充索引。 第一种方法是使用 Azure 搜索的 REST API 或 .NET SDK 将数据手动推送至索引。 第二种方法是将支持的数据源指向索引,让 Azure 搜索自动提取数据。
这里我们采用第一种方式,将数据推送到Azure Search的索引。这种方法只能通过SDK来实现,无法在门户中操作。
Azure 搜索识别的数据格式为 JSON,数据集中的所有文档必须包含可映射到索引架构中定义的字段的字段。
索引是 Azure 搜索服务使用的文档及其他结构的永久存储。 文档是索引中的一个可搜索数据单元。 例如,电子商务零售商可能有所销售每件商品的文档,新闻机构可能有每篇报道的文档。将这些概念对应到更为熟悉的数据库等效对象:索引在概念上类似于表,文档大致相当于表中的行。
在本节中,我们会读取上一个步骤中生成的RSS文件,每篇文章生成一个document传到Azure Search Index,这些操作会使用azure-search这个node.js插件来完成。
为了让索引识别我们的数据,我们必须先定义索引架构,也就是数据结构:有哪些字段,每个字段的数据类型是什么?是否可以被搜索、排序和过滤等。
var schema = {
name: indexName,
fields: [
{
name: 'id',
type: 'Edm.String',
searchable: false,
filterable: true,
retrievable: true,
sortable: true,
facetable: false,
key: true
},
{
name: 'title',
type: 'Edm.String',
searchable: true,
filterable: true,
retrievable: true,
sortable: true,
facetable: false,
key: false,
analyzer: 'zh-Hans.microsoft'
},
// ...
],
// ...
corsOptions: {
allowedOrigins: ['*']
}
};
在上面的代码中,定义了索引的架构,架构的详细解释请参考search-what-is-an-index。
这里面尤其要注意的是分析器analyzer的定义,一开始我用默认的英文的,对中文搜索怎么都不感冒,后来才注意到这个设置的问题。对于我的站点,必须用简体中文分词器,所有语言的分词器缩写请参考Language Support。
在代码最后,我们定义了corsOptions为*,代表这个查询可以从任何域名发起,你也可以根据安全策略,限制这个地址为某个域名或者IP地址。
结构定义完毕之后,就是创建索引和插入document数据了。
// delete index
searchClient.deleteIndex(indexName, function (err) {
if (err) console.error(err);
// create index
searchClient.createIndex(schema, function (err, schema) {
if (err) {
console.dir(err);
throw err;
}
each(posts, function(post, next) {
// add document to index
searchClient.addDocuments(indexName, [post], function (err, details) {
console.log(err ||
(details.length && details[0].status ? 'OK' : 'failed'));
next(err, details);
});
}, function (err) {
console.log('Finished rebuilding index.');
});
});
});
完整的代码请参考azure-search-buildindex.js
接下来,在本机执行下面这段node.js脚本,先通过npm安装依赖的模块,然后把数据提交给Azure Search索引。
npm install feedparser -g
npm install fs -g
npm install string -g
npm install azure-search -g
npm install async-each-series -g
npm install minimist -g
node azure-search-buildindex.js --rss <RSS_PATH> --search-url <URL> --search-key <KEY>
RSS_PATH:rss文件路径;URL:Azure Search的URL;KEY:azure search的key。
Azure Search 的URl如下图
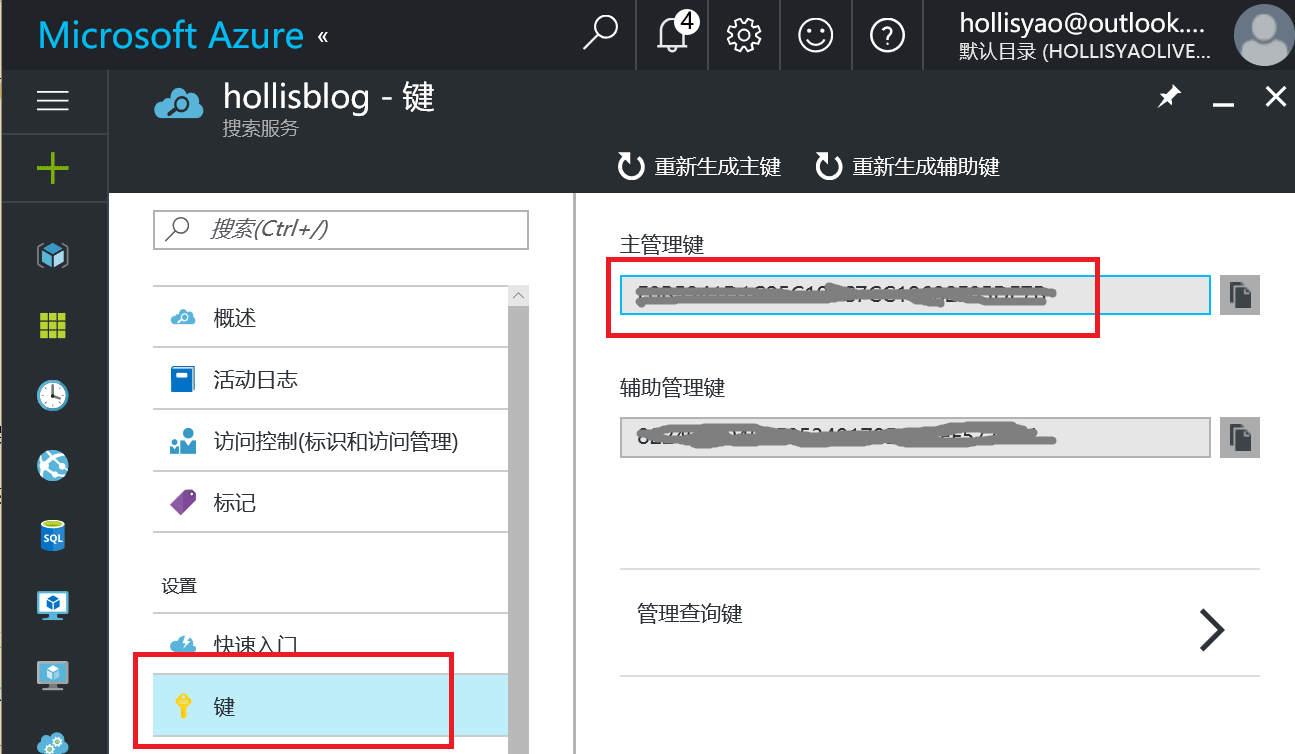
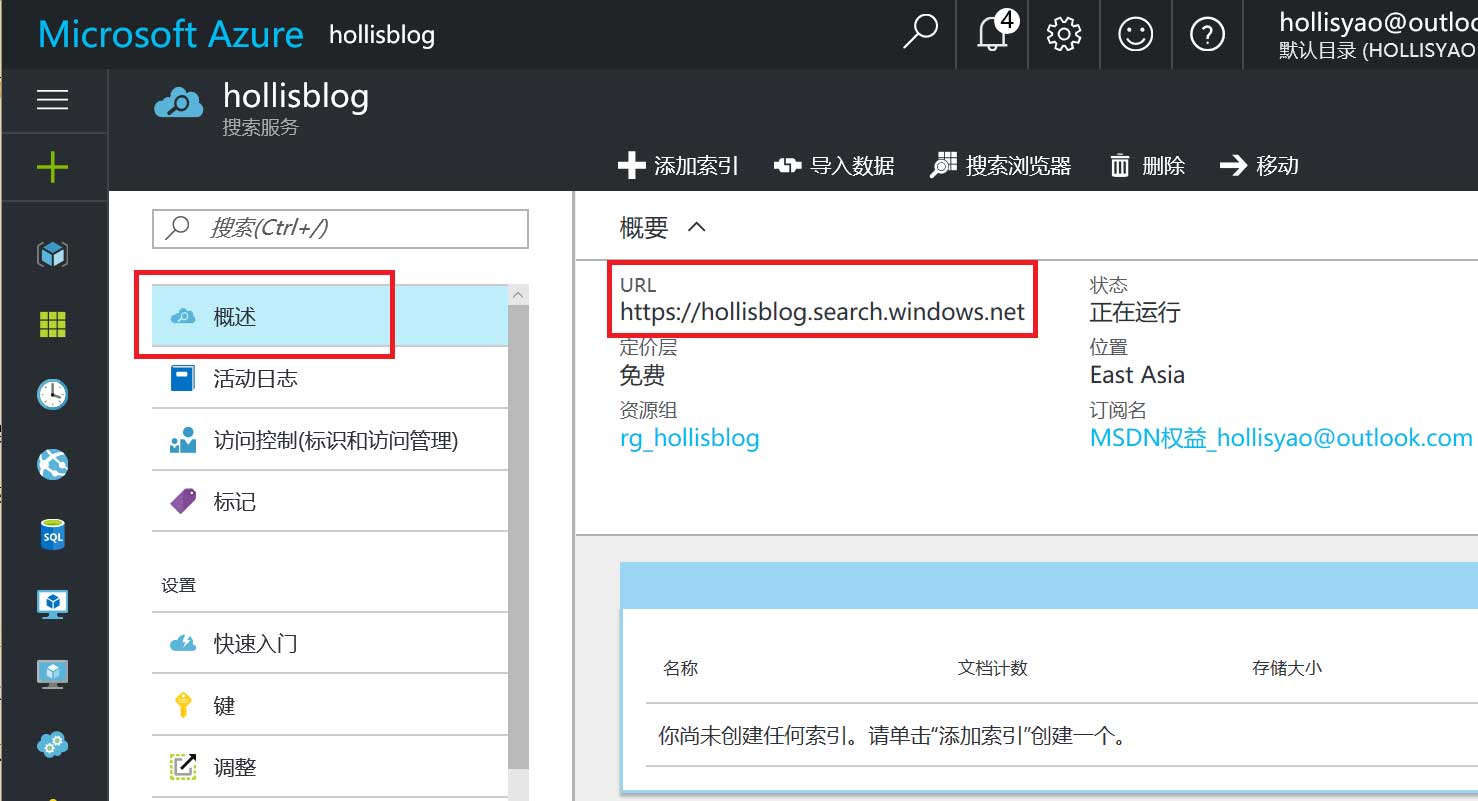 Azure Search 的Key如下图
Azure Search 的Key如下图
 我的环境中的示例命令如下:
我的环境中的示例命令如下:
node C:\Users\holyao\Documents\GitHub\hollisyao.github.io\js\azure-search-buildindex.js --rss C:\Users\holyao\Documents\GitHub\hollisyao.github.io\_site\allfeed.xml --search-url https://hollisblog.search.windows.net --search-key XXXXXXXXXXXXXXXXXXXXXXXXXX
我的search-key可不能告诉你们
上面这段脚本必须在每次新增或者修改文章之后,被执行一次,用来重新创建Azure Search索引。
在本机执行完毕这段脚本之后,在Azure Portal中查看,已经能看到索引被创建,并且有三篇测试博客被索引了。
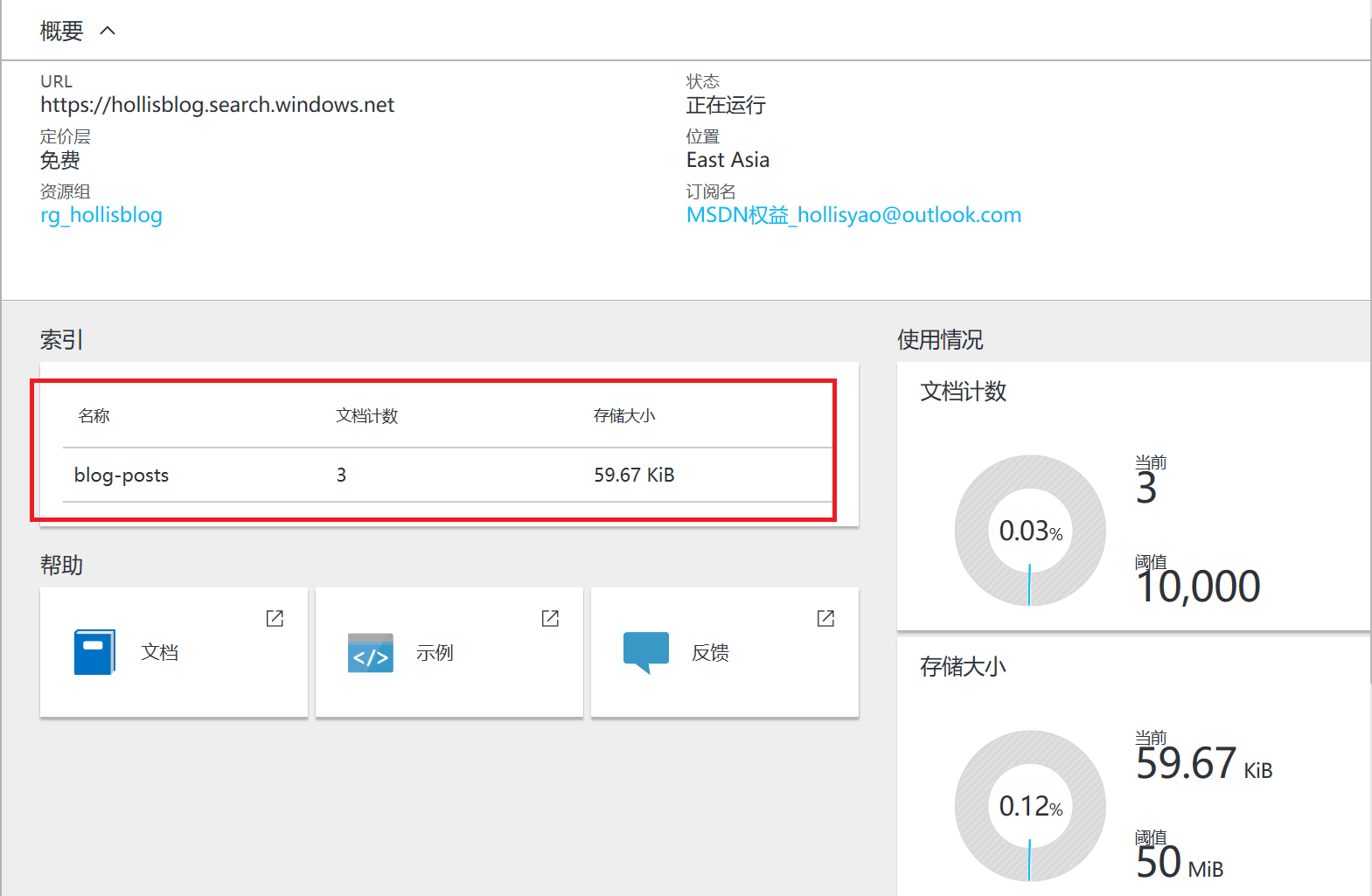
搜索索引
最后一步,就是在Jekyll网站中,添加一个页面,用客户端的Javascript脚本来搜索Azure Search的索引数据。 我先来写这个客户端脚本,我把它命名为:azure-search-results.js,关键代码如下:
function BlogSearchService() {
var svc = this;
var indexName = 'blog-posts';
var client = AzureSearch({
url: 'https://hollisblog.search.windows.net',
key:'XXXXXXXXXXXXXXXXXXXXXXXXXXXXX',
version: '2016-09-01'
});
//define a search property for BlogSearchService class
svc.search = search;
function search(query, callback) {
var searchOptions = { search: query, 'select': 'id, title, url, date',
'highlight': 'title, content',
'highlightPreTag': '<strong><em>', 'highlightPostTag': '</em></strong>' };
client.search(indexName, searchOptions, callback);
}
}
在这里使用了新版API的一些特性,比如highlight,就是能够突出显示命中关键字,这样只需要返回正文中命中部分就可以了,不需要返回全部的正文再截取。
完整的代码文件在这里azure-search-results.js (我的key还是暴露了 )
在上面的代码中用到了AzureSearch对象,这是一个nodejs对象,大家想想看,如果在纯客户端环境中,它还能执行吗?所以,在这里我们要使用azure-search的浏览器版本,浏览器版本可以在这下载,azure-search.min.js
脚本配置完毕之后,我们来写搜索的html页面,代码如下:
---
title: Search
layout: search
description: "Search Center"
---
<form action="/search" method="get" class="bs-example bs-example-form">
<!--<label for="search-box" style="display:hidden;">Search</label>-->
<div class="input-group">
<input type="text" id="search-box" name="query" class="form-control" placeholder="What are you looking for"/>
<span class="input-group-addon" style="padding: 0px;">
<input type="submit" value="Search" class="btn btn-primary" style="padding: 3.5px 20px;"/>
</span>
</div>
</form>
<ul id="search-results"></ul>
{% if site.azuresearch %}
<script src="/js/azure-search.min.js"></script>
<script src="/js/azure-search-results.js"></script>
{% else %}
<script>
window.store = {
{% for post in site.posts %}
"{{ post.url | slugify }}": {
"title": "{{ post.title | xml_escape }}",
"author": "{{ post.author | xml_escape }}",
"category": "{{ post.category | xml_escape }}",
"date": "{{ post.date | xml_escape }}",
"content": {{ post.content | strip_html | strip_newlines | jsonify }},
"url": "{{ post.url | xml_escape }}"
}
{% unless forloop.last %},{% endunless %}
{% endfor %}
};
</script>
<script src="/js/lunr.min.js"></script>
<script src="/js/search.js"></script>
{% endif %}
在这个页面中我们根据配置动态切换两种搜索引擎:lunjs和Azure Search。
配置参数在_config.xml中填写:
# Search settings
azuresearch: true #是否启用Azure Search搜索
到这里,所有的配置工作已经结束,你也可以在我的博客网站看到实际的效果。
参考资料: